1. "Minimalist" Literate Programming in graphein
1.1. Quick Abstract
If you're familiar with Literate Programming and Noweb, and the TEI, ...
graphein's "Minimalist" Literate Programming" (graphein MLP, or gMLP):
- Discards all of the weaving aspects of Noweb and uses straight TEI XML markup instead. This is not a "TEI/XML back-end for Noweb," but TEI as the LP source file markup language instead of "Noweb + a text markup langauge."
- Defines, in the TEI, entity attributes to mark up LP code chunks and references to code chunks.
- (Keeps the multiple-LP-per-file and multiple-file-per-LP possibilities of Noweb.)
- Discards all other aspects of LP and Noweb (e.g., no indexing or cross-referencing). This is what I mean by "minimalist," though I acknowledge that it may indeed be so minimal that it isn't really LP at all.
- Adds a bit of TEI markup to allow otherwise marked up code chunks to be ignored during tangling (allowing identical code chunks, often extracted into XML SYSTEM entities, to appear in multiple places).
- Requires the starting code chunk to be named (no asterisk).
- "Pre-tangles" (via XSLT) the TEI source to code-chunk-only intermediate Noweb format source.
- Uses notangle for subsequent tangling.
- Weaves the TEI source as ordinary graphein TEI texts (it doesn't use noweave ).
..., and if none of that made any sense at all, read on.
1.2. About Literate Programming
The concept of "Literate Programming" ("LP") originated with Prof. Knuth, and has been well discussed (and discussed well) by him and in the literature.
The graphein system provides a sort of a stripped-down core LP facility that I'll term "Minimalist" Literate Programming: "MLP" or "gMLP". (I make no assertion that Prof. Knuth would view what I'm doing here as Literate Programming at all.) Additionally, the graphein system itself is composed of tools written as (Minimalist) Literate Programs.
Before going further, I can't resist a wonderful quote by Patrick T. J. McPhee, cited on Norman Ramsay's Noweb (an LP tool) home page http://www.eecs.harvard.edu/~nr/Noweb/:
"Without wanting to be elitist, the thing that will prevent literate programming from becoming a mainstream method is that it requires thought and discipline. The mainstream is established by people who want fast results while using roughly the same methods that everyone else seems to be using, and literate programming is never going to have that kind of appeal."
The basic idea of Literate Programming is that what the computer reads isn't particularly relevant, but what the human reader of a program reads is. So the program and its explanation are integrated into a single logical package (possibly composed of many files, of course). The computer gets to read the computer bits. These appear as a network or web of individual chunks, all tangled together (from the point of view of traditional computer programming) within the source for a more human-readable document. The process of extracting them for the computer to read (creating something which would presumably be even more difficult for a human to read) is thus called "tangling." The human reader gets to read a (presumably nicely formatted) document which explains the program and which contains the bits of the program being explained divided up into chunks which reflect the way a human reader might wish to think about them, not how a computer program would need to arrange them. The process of generating this readable package is called "weaving."
"Weaving" just takes the (already interwoven, really) source and processes it into a presumably nicely presented form. "Tangling" is possible because the program is broken up into discrete chunks which all have names and which all refer to other chunks (which they then incorporate into themselves). The program becomes a web of chunks (Knuth's original system was named "WEB") and "tangling" is just the (automated) process of forming them into a single program source text, stripped of all of the documentation, ready to be compiled.
(I suppose in a way "weaving" deals with the pre-woven, and "tangling" is really untangling; it doesn't matter.)
The real problem in Literate Programming, for me, has always been that the computer-reader is one entity, and the human-reader is another, but I, the human writer, am neither of them. What I write as the Literate Programming source text is not the human-readable output (articles on Literate Programming tend to show only this beautiful output) but the rather messy source to the weaving, markup and all.
So the matter comes down to mastering markup language. Conceptually, there are two markup languages involved: one for marking up the documentation chunks and another to mark up the distinctions between documentation chunks and code chunks. Knuth's original WEB was relatively complex, though not overly so. It relied on his TeX text processing system for the documentation markup. Other LP tools have reduced this complexity, and some have to one degree or another decoupled these two domains of markup language.
The LP tool that I'll use here, "Noweb," consists of little more than markup which distinguishes documentation chunks from program chunks, together with a cross-reference facility. It is still tied to its documentation markup, but it doesn't specify the language of this markup. Rather, it assumes that the user will write in some markup language supported by a Noweb "back end" for that language. (A stock Noweb system comes with back ends which support, for example, (La)TeX and HTML.)
1.3. Minimalist Literate Programming
My markup language is the TEI, of course, and there is no Noweb back end for that. I could write one - the process is well documented and concise. I don't think I need to, however.
If I reduce Literate Programming beyond Noweb to its further-irreducible minimum, it seems that what I require is simply:
I can encode both of these in the TEI.
The documentation chunks are just the regular TEI encoding of my text.
Code chunks can be represented by a TEI <ab> entity with two attributes: type and id. The "type" attribute will assume the value "code-chunk", thus distinguishing this type of <ab> from the several others in use. The "id" attribute will simply be this code chunk's name (which is exactly what the XML/TEI "id" attribute is supposed to be - a unique entity identifier).
The links/references between code chunks which form the "web" of the code can be represented by TEI <seg> entities.
The process of "weaving" then disappears as a separate step: it's jut the ordinary XSL(T/-FO) processing of the document. The process of "tangling" becomes a straightforward two-step process. First, a separate XSLT transformation is made which strips out everything that isn't a code chunk and writes the contents of the code chunks out in Noweb form. This leaves a sort of a Noweb input file which contains only the code. Then I use Noweb's " notangle " program to tangle this into compilable program source (that's "no[web]-tangle", not "not-angle"). (The whole process is independent of the programming language. I'll use it for, at least, VARKON MBS, bash shell scripts, Awk scripts, and GNU make makefiles.)
Indeed, the present document is not simply a document. As will be seen later, it is actually not one but several (Minimalist) Literate Programs. Given the Minimalist LP of graphein, Literate Programs can go anyplace a document can.
1.4. Example
1.4.1. The Non-Literate-Programming Version
As an example, consider a Literate Programming approach to writing the following trivial shell script:
MSG="Hello, World!" if [ "$MSG" = "Hello, World!" ]; then echo "The message is $MSG" fi;
As shown above, this isn't yet a "literate program," but just a preview of the shell script itself. In other words, this is a literal copy of the program that should be tangled out of its gMLP source file or files (which, as it happens, will be this present document itself, which also contains/is several literate programs).
1.4.2. The Points I'll (Try To) Make
The points I want to make by re-presenting this trivial shell script in a ("Minimalist") Literate Programming version are these:
- Program documentation contains anything I can do ordinarily in any graphein document
- Code consists of multiple "code chunks"
- Code chunks can appear in any order
- Documentation "chunks" are everything that isn't a code chunk
These points imply a major simplification to standard Noweb. I abandon Noweb's cross-referencing facilities entirely. This really is "minimalist" Literate Programming; I can't imagine taking much more away and still being able to call the result LP (and perhaps even at this stage it isn't).
(The other simplification to Noweb is that I abandon Noweb's use of the asterisk character to specify the default starting chunk; more on that later.)
In any event, in the next section I'll do a "Minimalist" Literate Programming ("MLP" or "graphein MLP"/"gMLP") version of this shell script.
1.4.3. The ("Minimalist") Literate Programming Version
The first element of the MLP version is some documentation explaining the shell script. Well, this entire present document up to this point is already the first "documentation chunk" of this Literate Program. Like Molière's Monsieur Jourdain, we've been writing a Literate Program all along and never known it.
Ok, but now for some "real" LP: talking about this shell script itself. The core of this "hello, world" shell script is the section which uses the "test" command (syntax: [ ]) to check the contents of the MSG variable. Note that it is important to put the "$MSG" variable in quotes in the test. The shell simply expands it out to its literal text and without the quotes around the variable instance this would then parse as two separate words, "Hello," and "World!"
<<testmessage>>= if [ "$MSG" = "Hello, World!" ]; then << action>> fi;
But (in this somewhat stilted discussion of this program; stilted only because it's trivial and can be comprehended at a glance, but I'm pretending that it's difficult and needs to be explained) note something else: as presented as a Literate Program, this shell script "starts" in its middle. The "tangling" process will pull all of its pieces together and put them, automatically and invisibly, in the right order.
One thing that Literate Programming allows you to do is to focus on the interesting parts first. A standard principle in writing big poetic epics is to start not at the beginning, which can be dull, but in medias res, in the middle of things where it's exciting. So the Iliad doesn't start by recounting the years of inconclusive battles between the Achaeans and the Trojans which characterized most of the Trojan War. Instead, it starts nine years into it when Achilles throws a hissy fit and things start to get interesting.
Note also that there isn't any strict pairing of code chunks and documentation chunks. Any number of documentation paragraphs, lists, or other TEI elements can appear before, between, or after code chunks. Code chunks can follow each other directly. Code chunks can appear anywhere that block-level elements can appear in a TEI document (anywhere a paragraph could go). From the TEI's point of view, the code chunks are just slightly different paragraphs.
The code chunk above has two interesting parts to it, aside from the shell script code itself.
The first of these is its own name, "testmessage". As I'll show in the next section, I didn't write, literally, "<<testmessage>>=". Instead, I coded something else with TEI tags, and the XSL transformation of the underlying TEI encoding used for this code chunk enclosed this name automatically in double-angle-brackets (which is the Noweb convention) and put an "=" after it, just to label the code chunk nicely.
The second interesting part is the reference to another code chunk, one named "action", within this code chunk. Tangling is a bit like macro processing: notangle will substitute the contents of the chunk "action" at the point where it is referenced here.
So what is this referenced code chunk? Here it is:
<<action>>= echo "The message is $MSG"
Not much to it. This is, after all, simply a trivial "hello, world" type of program.
It's easy to see how these two piece fit together, but where is the (no)tangle process to start, when it tries to tangle-out a real shell script? In Noweb, I can either name the main code chunk (and then specify that name to notangle) or I can use an asterisk for a default main code chunk. Since the asterisk isn't allowed by XML as a character in "id" attribute values, I'll forsake the Noweb asterisk convention and simply name all code chunks. So here's the beginning code chunk:
<<hello.sh>>= MSG="Hello, World!" << testmessage>>
And actually, it's now done. When I start notangle, I'll tell it to use this chunk as the starting chunk. This starting chunk chunk both does some startup-type things (sets the variable "MSG") and references the "testmessage" code chunk, from which, as it happens, all of the rest of the program springs follows in a web (a tree, really).
A tiny little example such as this can illustrate the principles of (Minimalist) Literate Programming, but it can't really demonstrate their usefulness. This shell script is small enough to be comprehended at a glance. Literate Programming excels in areas where the program is too complex to be comprehended instantly. The order of a program in a programming language is determined by the logical necessities of that language (e.g., define your vegetables first). Literate Programming posits the idea that the logical order of the presentation of the problem the program solves may be very different, and should be the order of the program as it is read.
1.4.4. But What Did I REALLY Write?
The section above tried to illustrate LP from a reader's perspective, which is the way it's usually illustrated. But I didn't actually write what you literally read as formatted text above, much less its encoding in HTML (or PDF, or whatever). What I really wrote was a TEI compliant source text.
The documentation chunks were (are) just ordinary "graphein TEI." They are in no way even identified as being a part of a Literate Program.
The code chunks are encoded not in Noweb's syntax (the double-angle-brackets, for example) but as TEI entities. There are only two types of these entities: code chunks and references to code chunks.
Code chunks are defined using the TEI <ab> entity, with a "type" attribute with the value "code-chunk" and an "xml:id" attribute whose value is the name of the chunk. Thus, what I literally wrote for the "action" chunk looked like this:
<ab type="code-chunk" xml:id="action"> echo "The message is $MSG" </ab>
Code chunk references are defined using the TEI <seg> entity, with a "type" parameter whose value is the name of the code chunk being referenced. Thus:
<seg type="code-chunk-ref">testmessage</seg>
That's it. Because I've abandoned almost everything else in LP (no cross-reference generation, for example), this is all it takes to encode a "Minimalist" Literate Program within a graphein TEI document.
The XSLT processing of this to prepare it for Noweb's notangle, and the running of notangle in the "make" process, are described elsewhere.
1.4.5. Multiplicity
Literate Programming, at least in its Noweb version, allows considerable flexibility with regard to where code chunks are located. gMLP does so as well. For the most part, I get this flexibility "for free" from Noweb, but there is one additional TEI encoding element I introduce to enable just a bit more flexibility still.
A single gMLP source document may contain more than one Literate Program. This present document does so. The tangling process extracts each program out of the document (actually out of an intermediate XSLT-processed form; see below) by specifying the name of its starting code chunk. Noweb's notangle does the rest automatically.
A single gMLP program may be divided between multiple source documents. Noweb's notangle simply takes multiple input files and tangles out the program from them.
I find it useful, in addition, to be able to use the same code chunk in multiple source documents. This isn't the same as splitting the program between documents (each of which would presumably get a distinct set of code chunks). Rather, I wish to be able to use one code chunk in two (or more) places for reasons of documentation, yet have it appear only once in the actual gMLP program.
As an example of this, consider a code chunk from the "weaving" makefile for graphein itself:
<<target-dependencies>>= $(HTMLS): %.html : %.tei $(STATIC_FILES) $(LINKING_IMAGES) dependencies.dep images-scaled.dep
This code chunk defines a single GNU make target, and so is logically a single object which ought to appear in a single code chunk. However, it sets up a target which has dependencies of types which are discussed most logically in two different source documents (that is, all of the regular dependencies, and then also the "scaling" dependencies).
I could of course simply define/use it in one document and copy this into another. But this introduces the classic "multiple update" problem - if I change it at one location, will I remember to duplicate that change in the other? So it's best to use the TEI/XML "SYSTEM entity" mechanism to define it as a SYSTEM entity in its own file and then include it by reference in each document.
Noweb, however, handles multiple code chunks of the same name in a manner which doesn't allow this. I would want Noweb it to discard the duplicates. Instead, Noweb concatenates multiple code chunks of the same name. (In other contexts, I should note, this is a positive feature of Noweb; it just doesn't suit here, and "here" is a pretty weird way of using Noweb.)
I could, as a workaround, put only the actual code contents of this code chunk in the SYSTEM entity file, and wrap either the gMLP "code chunk" <ab> block around it (for the time when it's to be tangled) or some other TEI presentational block (for the time(s) when it is not to be tangled.) This has two (possibly imaginary?) drawbacks. Aesthetically, the multiple uses wouldn't look the same unless I created a special "code chunk, but really only a reference" <ab> attribute. Logically, each usage is a real definition/use of the chunk - there's no logical reason, a priori, to privilege one over another.
What I've done instead is to define another type of <ab>, type="do-not-tangle". It means that anything inside it (at any depth, though in practice it'll usually just contain code chunks one XML level down) will be kept and processed as such in the woven output but omitted entirely from the tangled output.
So for this example, I'd write up the code chunk itself in its own file, target-dependencies.tei-entity, which would contain, literally:
<ab type="code-chunk" xml:id="target-dependencies"> $(HTMLS): %.html : %.tei $(STATIC_FILES) dependencies.dep images-scaled.dep </ab>
In each file where this entity is to be used, in the initial "DOCTYPE" section, I add a definition of this entity:
<!DOCTYPE TEI PUBLIC "-//TEI P5//DTD Main Document Type//EN" "tei.dtd" [ <!ENTITY % TEI.header "INCLUDE"> <!ENTITY % TEI.core "INCLUDE"> <!ENTITY % TEI.textstructure "INCLUDE"> <!ENTITY % TEI.linking "INCLUDE"> <!ENTITY % TEI.dictionaries "INCLUDE"> <!ENTITY % TEI.figures "INCLUDE"> <!ENTITY % TEI.tagdocs "INCLUDE"> <!ENTITY % TEI.XML "INCLUDE"> <!ENTITY target-dependencies SYSTEM "target-dependencies.tei-entity"> ]>
To use this entity as an actual code chunk, I just refer to it:
&target-dependencies;
Used as such, it'll show up both in the woven and in the tangled outputs.
To use this entity in the woven documentation only, I'd wrap it in a "do-not-tangle" tag:
<ab type="do-not-tangle"> &target-dependencies; <ab>
Used as such, it'll show up only in the woven output, not in the tangled output.
1.4.6. Weaving
Weaving the human-readable document from the TEI source is trivial (given the rest of the graphein system). The documentation chunks are already TEI. The code chunks are encoded in TEI. So it's just normal TEI processing - there is no explicit "weaving" process at all. So, actually, my "minimalist" LP use of Noweb doesn't even use the noweave program. It feels almost like cheating.
1.4.7. Tangling
Tangling the program out of the TEI source is a little trickier (but not much). While weaving is really just normal XSLT processing, as described above, tangling is a non-document process. It requires the knowledge of things which are larger than documents (such as which set of documents contains the whole of the program source) or simply other than documents (such as which compiler should be run on the tangled output (or indeed if a compiler should be run at all) and where the final executables should reside. Because of this, it is not handled by the regular graphein makefile, but instead is handled in ad hoc makefiles and possibly shell scripts.
The process, orchestrated by this makefile, is this:
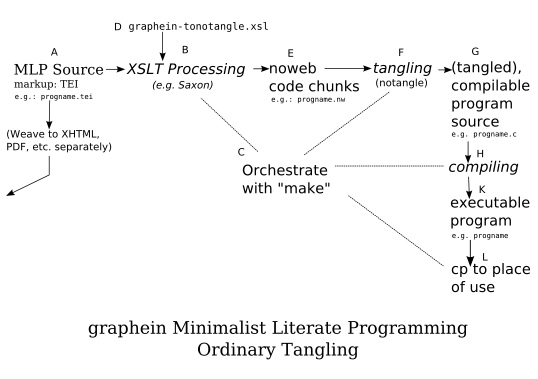
graphein MLP: Ordinary Tangling
The starting place is labelled "A" on the drawing above: the graphein TEI encoded "Minimalist Literate Programming" source file itself.
The first step in tangling the program out of this source is B, the XSLT processing. This is done by an XSLT processor (of course), such as Saxon. It requires as simultaneous input an XSL "stylesheet" which specifies the transformation steps it should take. For graphein MLP, this is " graphein-tonotangle.xsl". This step (and the others) could be run manually, but for convenience they will in practice be orchestrated by a combination of bash shell scripts and make (more on this later).
The output of this XSLT processing is a file of Noweb-encoded code chunks. The filename of this file is supplied by the shell script (it is not encoded in the source), and by convention will bear a " .nw" suffix. At this point, the program is just like a conventional Noweb input file, except that, curiously (for Noweb), it has only code chunks and no documentation chunks.
These Noweb code chunks are then run through Noweb's notangle program, at point F of the diagram above. Again a controlling shell script and makefile combination orchestrates this. The output from this step, at G, is the tangled, compilable, source code for the program.
At this stage, the tangling process itself is done. For convenience, the shell script / makefile may orchestrate zero or more of the following steps as well.
At point H in the diagram, it may compile the program. At point L it may cp the executable to some location in which it will be used. Or it might skip the compilation and simply copy the program's source code to some location of use.
1.5. graphein-tonotangle.xsl (gMLP Version)
1.5.1. graphein-tonotangle.xsl: The Process
The core of this tangling is an XSLT "stylesheet" (an XSLT "program," sort of, though XSL purists would wince at this) which matches and extracts (only) the code chunks. The process of tangling it is really no different from the regular process, but it can be confusing because sometimes the names are duplicated (I'm extracting the program which I use to extract itself with; confusing its name at one time with its name as a different thing at another time is a hazard of bootstrapping). It also introduces one of the difficulties (a minor one, I insist!) of this graphein MLP approach: encoding the less-than ("<") and greater-than (">") characters can be tricky.
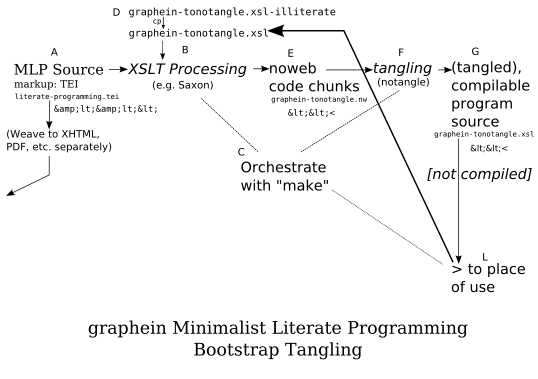
Figure: graphein MLP: Bootstrap Tangling
The MLP Source in this process is the source version ( .tei version) of the document you're reading right now. (The presentation of this XSLT script/program/stylesheet/whatever is itself an illustration of the potentially "stealth" nature of LP. You can sneak into a Literate Program almost without noticing it.)
1.5.2. graphein-tonotangle.xsl: Bootstrapping Issues
The bootstrapping issue comes up immediately. I'm trying to extract the XSL program " graphein-tonotangle.xsl" out of this present " literate-programming.tei" source file. But to do that, I need " graphein-tonotangle.xsl". There's no way around this: it's an issue with all bootstrapping. Bootstrapping is possible, but you need at least a little bit of handwritten code to get started.
Fortunately, " graphein-tonotangle.xsl" is not long. I've supplied, as a part of the graphein distribution, a handwritten version of it. (I cannot resist naming it " graphein-tonotangle.xsl-illiterate"; - hey, I can cast slurs upon my own writing with impunity!) To use this handwritten version, I simply copy it to (or rename it as) " graphein-tonotangle.xsl" and then run the XSLT Processing step ("B" in the diagram). The cp ("D" in the diagram) is a by-hand process, but from then on the regular controlling shell script works.
The output from this XSLT processing, at E, is a Noweb of code chunks (" graphein-tonotangle.nw") which is tangled normally with notangle . The output from this process is " graphein-tonotangle.xsl", which (unless there are file permissions issues) simply overwrites the existing copy of the "illiterate" version. (Alternatively, it can be (no)tangled by hand and called something else, and then copied to " graphein-tonotangle.xsl"). In either case, this newly generated " graphein-tonotangle.xsl" program ("XSLT stylesheet") should be copied to the root directory of whatever documentation hierarchy it will be used in.
1.5.3. graphein-tonotangle.xsl: Character Encoding/Escaping Issues
The other issue is one of text/character encoding, and has to do with the over-use of the left and right angle brackets ("<" and ">"; the less-than and greater-than symbols). They're used in the TEI markup sitting underneath this page, because the TEI is defined in XML. Normally, I could just "escape" them by using XML "character entities" such as the ampersand-l-t-semicolon sequence ("<"). But here they're also used in the content of the code chunk itself, because it is an XSLT "stylesheet" and XSLT is defined in, of course, XML. And, wouldn't you know it, Noweb also uses these signs (doubled, at that), so that the XSLT embedded in this present TEI must, itself, generate angle-brackets in Noweb. The fact that the result of this LP exercise is XSLT code which itself will, when used, generate Noweb complicates this further.
The final output from notangle must be XSLT code. It needs to have literal paired single left and right angle characters (ASCII 0x3C and 0x3E) around its XSLT entities; that's how XML-defined languages are marked up. So when it, in its own use, also needs to emit these left and right angle characters as output, it needs to represent them in some other way in its own source code so that they're not mistakenly parsed as XSL markup. The conventional way to do this, so far as I know, is to use the predefined XML entities "<" (ampersand-l-t-semicolon) and ">" (ampersand-g-t-semicolon). (Actually, the closing member of this pair, ">", might be ok as such, but I find it clearer simply to encode both as XML entities.)
So a line of this XSLT program which should emit, for example, the results of an "xsl:value-of" statement would just use the regular literal "<" (ASCII 0x3C) and ">" (ASCII 0x3E) characters to encode the xsl:value-of entity:
<xsl:value-of select="@xml:id" />
[Whatever you do, don't do a "View Source" and look at the actual encoding of the above, which is a visual representation of such a statement and not the thing itself. No, don't do it!]
However, if the output that this statement generates must be preceded and followed by Noweb-style double angles (as it must), just writing these literally before and after won't work. That is, this will fail:
<<<xsl:value-of select="@xml:id" />>>
The problem is that the XSLT processor will try to interpret this Noweb markup as XSL(T) markup. In order to avoid this, the Noweb markup must be encoded in this XSLT program as XML character entities. So:
<<<xsl:value-of select="@xml:id" />>>
I've indicated this in the Figure earlier by writing "<<<" at "G".
So long as notangle doesn't detect matching sets of pairs of doubled angles, it treats everything ast literal text. This is the case here. So the input to notangle ("E" in the diagram) is actually the same. There is no need to add any special escaping/encoding for notangle itself. (Whew!)
This is not true of the XSLT Processing step. If I just used this sequence as input to it (at "B" in the diagram), the XSLT processor would be confused in two ways.
First, it would see the "<xsl:value-of select="@xml:id" />" and try to interpret it as a part of its own XSLT processing (rather than emitting it as output, which is what I want it to do). To avoid this, these angle brackets must be "escaped" as XML character entities. So:
<xsl:value-of select="@xml:id" />
Second, the XSLT processor would see the Noweb "<<...>>", recognize them as XML character entities, and output them as literal characters ("<<...>>").
What I must do, then, is "escape" these character entities a second time so that they'll not be recognized as character entities by the XSLT processor, but so that the XSLT processor will output the right characters such that they become character entities.
To do this, I take the ampersand which distinguishes these as character entities and encode this ampersand itself as a character entity ("&"). So the example line becomes:
&lt;&lt;<xsl:value-of select="@xml:id" />&gt;&gt;
(You really really don't want to do a "View Source" on the line above :-)
I've noted this at "A" in the diagram.
So, basically, every time a graphein MLP source file needs to encode in its source what will become "<" in its output, it must escape this by using "<", and every time it needs to encode in its source what will become "<" in its output, it must double-escape this by using "&lt;".
1.5.4. graphein-tonotangle.xsl: Core Templates
Here, then, are the two code chunks which implement graphein MLP.
<<match-code-chunk>>= <xsl:template match="tei:ab[@type='code-chunk']"> <xsl:if test="not(ancestor::tei:ab[@type='do-not-tangle'])"> <<<xsl:value-of select="@xml:id" />>>=<xsl:apply-templates/> </xsl:if> </xsl:template>
<<match-code-chunk-ref>>= <xsl:template match="tei:seg[@type='code-chunk-ref']"> <<<xsl:apply-templates/>>></xsl:template>
That's it, really. That's all it takes to implement Minimalist Literate Programming in graphein.
1.5.5. graphein-tonotangle.xsl: Other XSL Stuff
The rest of the XSLT is just busywork, really. The overall structure is:
<<graphein-tonotangle.xsl>>= << xml-header>> << stylesheet-opening>> << setup>> << process-rest-of-document>> << match-code-chunk>> << match-code-chunk-ref>> << stylesheet-closing>>
And here are these busywork-bits. Literate Programming can't dispense with them; it simply allows them to be swept away to the end.
<<xml-header>>= <?xml version="1.0" encoding="utf-8" ?>
<<stylesheet-opening>>= <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:tei="http://www.tei-c.org/ns/1.0" version="1.1">
Closing the XSLT "stylesheet" simply means supplying the end tag.
<<stylesheet-closing>>= </xsl:stylesheet>
"Setup" consists of selecting the XSL output method and telling the XSLT processor to strip whitespace from all elements. Stripping whitespace isn't necessary ( notangle doesn't care), but it makes it easier to read the tangled output in those rare cases when I do.
<<setup>>= <xsl:output method="text" encoding="utf-8" /> <xsl:strip-space elements="*" />
Finally, we need to get to the code chunks, but ignore everything in the document that isn't a code chunk. This means that we must process everything that could lead down the document tree to a code chunk, but at that level to discard everything else.
<<process-rest-of-document>>= << get-to-chunk-level>> << ignore-nonchunk-entities>>
<<get-to-chunk-level>>= <xsl:template match="/"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:TEI"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:text"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:body"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:div"><xsl:apply-templates /></xsl:template>
Of the various entities to be discarded, the only one that bears special mention is the last: <ab>. The template for it matches all <ab> except those distinguished by a type="code-chunk" attribute.
<<ignore-nonchunk-entities>>= <xsl:template match="tei:teiHeader"></xsl:template> <xsl:template match="tei:front"></xsl:template> <xsl:template match="tei:back"></xsl:template> <xsl:template match="tei:head"></xsl:template> <xsl:template match="tei:p"></xsl:template> <xsl:template match="tei:list"></xsl:template> <xsl:template match="tei:table"></xsl:template> <xsl:template match="tei:figure"></xsl:template> <xsl:template match="tei:bibl"></xsl:template> <xsl:template match="tei:ab"></xsl:template>
1.6. graphein-tonotangle.xsl ("Illiterate" Version)
graphein-tonotangle.xsl-illiterate
(Click-and-save the link above; don't cut-and-paste the text below, or you'll get escaped angle brackets as XML entities.)
<?xml version="1.0" encoding="utf-8" ?> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:tei="http://www.tei-c.org/ns/1.0" version="1.1"> <xsl:output method="text" encoding="utf-8" /> <xsl:strip-space elements="*" /> <xsl:template match="/"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:TEI"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:text"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:body"><xsl:apply-templates/></xsl:template> <xsl:template match="tei:div"><xsl:apply-templates /></xsl:template> <xsl:template match="tei:teiHeader"></xsl:template> <xsl:template match="tei:front"></xsl:template> <xsl:template match="tei:back"></xsl:template> <xsl:template match="tei:head"></xsl:template> <xsl:template match="tei:p"></xsl:template> <xsl:template match="tei:list"></xsl:template> <xsl:template match="tei:table"></xsl:template> <xsl:template match="tei:figure"></xsl:template> <xsl:template match="tei:bibl"></xsl:template> <xsl:template match="tei:ab"></xsl:template> <xsl:template match="tei:ab[@type='code-chunk']"> <xsl:if test="not(ancestor::tei:ab[@type='do-not-tangle'])"> <<<xsl:value-of select="@xml:id" />>>=<xsl:apply-templates/> </xsl:if> </xsl:template> <xsl:template match="tei:seg[@type='code-chunk-ref']"> <<<xsl:apply-templates/>>></xsl:template> </xsl:stylesheet>
1.7. Bootstrapping gMLP by Hand
To run the bootstrapping process by hand:
Create a simple shell script to run the XSLT processor. Here is one, which will end up being called "run-saxon.sh" once the "makefile-tangle" gets through extracting it.
<<run-saxon.sh>>= java \ -classpath "/usr/share/java/xerces-j2.jar:/usr/share/saxon-6.5.3/saxon.jar:/usr/share/java/xml-commons-resolver-1.1.jar:/etc/java/resolver" \ com.icl.saxon.StyleSheet \ -x org.apache.xml.resolver.tools.ResolvingXMLReader \ -y org.apache.xml.resolver.tools.ResolvingXMLReader \ -r org.apache.xml.resolver.tools.CatalogResolver \ -u \ $1 graphein-tonotangle.xsl
(The "-classpath" line is one long single line, not two or more.)
The Saxon XSL processor and the XML Commons Resolver need to have been set up on your machine. Or you can use any other XSLT processor, as you wish.
cp graphein-tonotangle.xsl-illiterate cp graphein-tonotangle.xsl chmod +w graphein-tonotangle.xsl ./run-saxon.sh literate-programming.tei > graphein-tonotangle.nw notangle -Rgraphein-tonotangle graphein-tonotangle.nw > graphein-tonotangle.xsl
Now re-run the XSLT processing, using the newly generated graphein-tonotangle.xsl". The output should be identical to " graphein-tonotangle.xsl-illiterate".
./run-saxon.sh literate-programming.tei > temp.nw notangle -Rgraphein-tonotangle temp.nw > temp.xsl diff temp.xsl graphein-tonotangle.xsl
(Since the nominally handwritten " -illiterate" version, " graphein-tonotangle.xsl-illiterate", is, as distributed with graphein, really one generated (by an earlier truly handwritten version, not supplied) by the present MLP source, the results should be identical down to the whitespace.)
1.8. Orchestrating the Tangle: makefile-tangle
1.8.1. Why Tangling is Separate
The tangling process is an ideal candidate for GNU make (as is the weaving process, described elsewhere). However, while it is possible to encapsulate the weaving process entirely in a single makefile common to all directories, the same is not true for the tangling process. Tangling requires a knowledge not only of which source ( .tei) files require tangling (which could be determined automatically) and what programming languages their code chunks are written in (which could be determined, or encoded), but also of external issues such as compiler parameters (directives, include files, libraries - which may differ in different operating system environments) and the intended location of use of the compiled output (especially relevant for gMLP VARKON MBS, the running of which may be incorporated back into the source documents).
For now at least, then (and I may change my mind later), I'll simply use a separate makefile in each directory. I'll call this the same thing in each directory, " makefile-tangle", but it may/probably will be different in each. The model here, which is the makefile-tangle for graphein itself, may be copied, modified, and used as necessary. This can be done either by literally copying and modifying " makefile-graphein" or by taking the gMLP source for the present section of this document. (This section has been written in a separate file, " makefile-tangle.tei-entity ", which may be copied and used as a gMLP source.)
Once again, I'll use gMLP techniques to put the most important parts first. Perhaps more accurately, I'll put the tricky bit first.
1.8.2. Trickery, and a Script to Run It
An XML "SYSTEM entity" is an external piece of text (usually, and here, a file, though in theory not necessarily) encoded in a markup langauge defined by XML (such as the TEI). The graphein system allows the possibility of XML SYSTEM entities. They can be handy, for example, for cutting up a document into chapters, one chapter per system entity. (The present section of this chapter, for example, is sitting in an XML SYSTEM entity, just to make it separable from the rest of the chapter at a source level.) Because the graphein make (weaving) process automatically detects TEI files, XML system entities (which aren't standalone, but are incorporated as part of TEI files) can't have the " .tei" extension. By convention, graphein uses " .tei-entity" - clunky, but obvious.
The problem is detecting in the make process when a document has changed when only the .tei-entity" file referenced by the document has changed.
There's no way to do this with XSL. By the time the XSL processor sees the input, the XML parser has resolved and incorporated all SYSTEM entities. It must be done at XML parse time.
What I need, then, is a way which goes into a TEI file and detects all of the external SYSTEM entities it uses. Here's a bit of trickery to accomplish this:
xmllint --debug index.tei 2> /dev/null | \
awk '{if (substr($1,1,10) == "ENTITY_REF") { \
printf("%s.tei-entity ", substr($1,12,length($1)-12))}}'
What this does is use the xmllint tool to parse the TEI (and all of the SYSTEM entities it uses), outputting a parsed tree as if debugging. Any actual error messages are thrown away (" 2> /dev/null" redirects stderr to the bit bucket). The rest of the tree is passed through an Awk script which detects those lines in the debugging output which are of the form " ENTITY_REF(entityname)" and returns only the " entityname" part. This is the base name of the external SYSTEM entity - add " .tei-entity" to it and the result is the filename.
Naively, I might just put this in the right-hand side of a GNU make rule, but that won't work. To do so, I'd put it in a GNU make " $(shell )" function call. But GNU make evaluates all functions at its invocation. By the time it gets around to working through the rule dependencies, all of the functions have been called already.
I could (and will) put this into a bit of bash shell code which cycles through all of the " .tei" files and, for each, cycles through all of the " .tei-entity" SYSTEM entities (if any). If any TEI file calls a SYSTEM entity that is newer than itself, I touch that file. This is enough to trigger a rebuild later.
The only trouble with this is that I can't figure out how to force GNU make to execute a particular target first. Unless I can do that, it may execute after other targets which are supposed to rely upon what it does - not good.
My solution here is crude, alas. I put this bit of trickery in a shell script and use that shell script to, then, execute make.
<<run-make-tangle.sh>>=
for tei_file in `ls *.tei`; \
do \
for tei_entity_file in `xmllint --debug $tei_file 2> /dev/null | awk '{if (substr($1,1,10)
== "ENTITY_REF") { printf("%s.tei-entity ", substr($1,12,length($1)-12))}}'`; \
do \
if [ $tei_entity_file -nt $tei_file ]; then \
touch $tei_file; \
fi; \
done; \
done
make -r -f makefile-tangle $1
I try to avoid writing code that feels sneaky, but this sure does.
There are two other situations in which I'll need to do nearly identical things: when weaving (only) and when both weaving and tangling. The shell scripts for these differ only in their line invoking make. Since I've just explained all of this here, I'll include them here, too.
<<run-make-weave.sh>>=
for tei_file in `ls *.tei`; \
do \
for tei_entity_file in `xmllint --debug $tei_file 2> /dev/null | awk '{if (substr($1,1,10)
== "ENTITY_REF") { printf("%s.tei-entity ", substr($1,12,length($1)-12))}}'`; \
do \
if [ $tei_entity_file -nt $tei_file ]; then \
touch $tei_file; \
fi; \
done; \
done
make -r -f makefile $1
Note that the makefile for weaving is called just "makefile" (because it is what gets done in ordinary graphein making, without gMLP) rather than "makefile-weave" (which would have been more a parallel with "makefile-tangle").
<<run-make-weave-and-tangle.sh>>=
for tei_file in `ls *.tei`; \
do \
for tei_entity_file in `xmllint --debug $tei_file 2> /dev/null | awk '{if (substr($1,1,10)
== "ENTITY_REF") { printf("%s.tei-entity ", substr($1,12,length($1)-12))}}'`; \
do \
if [ $tei_entity_file -nt $tei_file ]; then \
touch $tei_file; \
fi; \
done; \
done
make -r -f makefile-tangle $1
make -r -f makefile $1
1.8.3. makefile-tangle
The rules that do the actual work are much simpler. Here is the core of the makefile, a set of GNU make targets to make each type of program (e.g., bash shell script, GNU make makefile, XSLT stylesheet, etc. as required).
Note (Noweb): The default behavior for notangle is to expand tabs to 8 blank spaces. GNU make requires tabs in its rule actions. So when tangling this, be sure to specify the " -tN" parameter to notangle (" -t8" works). Depending on the weaving process, the tabs may or may not be visible below; they're there in the source.
<<targets-by-type>>= TARGETS_BASHES_MLP=hello.sh run-saxon.sh \ run-make-tangle.sh run-make-weave.sh run-make-weave-and-tangle.sh # generate-dependencies.sh TARGETS_BASHES_WEAVE= TARGETS_MAKEFILES_MLP= makefile-tangle TARGETS_MAKEFILES_WEAVE= TARGETS_XSLTS_MLP=graphein-tonotangle.xsl TARGETS_XSLTS_WEAVE= TARGETS_XMLS=xml-catalog bashes: $(TARGETS_BASHES_MLP) $(TARGETS_BASHES_WEAVE) makefiles: $(TARGETS_MAKEFILES_MLP) $(TARGETS_MAKFILES_WEAVE) xslts: $(TARGETS_XSLTS_MLP) $(TARGETS_XSLTS_WEAVE) xmls: $(TARGETS_XMLS) << make-bashes>> << make-makefiles>> << make-xslts>>
The various targets above include all of the code components of the graphein system (not just the ones required for gMLP). So, for example, TARGETS_BASHES_MLP includes not only "run-make-tangle.sh" (used in the gMLP part of graphein) but also "generate-dependencies.sh" (used in scaling images during weaving).
<<make-bashes>>= $(TARGETS_BASHES_MLP): make.nw literate-programming.nw scaling.nw notangle -t8 -R$@ make.nw literate-programming.nw scaling.nw > $@ chmod +x $@
<<make-makefiles>>= $(TARGETS_MAKEFILES_MLP): literate-programming.nw notangle -t8 -R$@ literate-programming.nw > $@
<<make-xslts>>= $(TARGETS_XSLTS_MLP): literate-programming.nw notangle -t8 -R$@ literate-programming.nw > $@
<<make-xmls>>= $(TARGETS_XMLS): text-processors.nw notangle -t8 -R$@ text-processors.nw > $@
All of these depend on a rule to make the Noweb intermediate files:
<<make-code-chunks>>= BASENAMES_TEI=$(basename $(wildcard *.tei)) TARGETS_NW=$(patsubst %,%.nw,$(BASENAMES_TEI)) $(TARGETS_NW): %.nw : %.tei java \ -classpath "/usr/share/java/xerces-j2.jar:/usr/share/saxon-6.5.3/saxon.jar:/usr/share/java/xml-commons-resolver-1.1.jar:/etc/java/resolver" \ com.icl.saxon.StyleSheet \ -x org.apache.xml.resolver.tools.ResolvingXMLReader \ -y org.apache.xml.resolver.tools.ResolvingXMLReader \ -r org.apache.xml.resolver.tools.CatalogResolver \ -u \ $*.tei graphein-tonotangle.xsl > $*.nw
Finally, every makefile should be able to clean up after itself. It should be safe to remove all Noweb files (" .nw"), as they're only used as intermediate files. It is probably not safe to remove all shell scripts by the " .sh" suffix, as I (or you) may have written entirely unrelated shell scripts that shouldn't simply disappear. The same is true of XSL(T) (" .xsl") stylesheets. So remove them by name, and also remove by name the generated makefiles (which have no filename suffixes).
<<clean>>= clean: rm -f *.nw rm -f $(TARGETS_BASHES_MLP) $(TARGETS_BASHES_WEAVE) rm -f $(TARGETS_MAKEFILES_MLP) $(TARGETS_MAKEFILES_WEAVE) rm -f $(TARGETS_XSLTS_MLP) $(TARGETS_XSLTS_WEAVE)
<<makefile-tangle>>= all: bashes makefiles xslts xmls << targets-by-type>> << make-code-chunks>> << clean>>
1.8.4. gMLP Distribution Items
So, after all of this, what does the standard distribution of the MLP portion of graphein contain?
First, it contains the minimal items out of which it can be re-created:
- literate-programming.tei
- makefile-tangle.tei-entity
- target-dependencies.tei-entity
- graphein-tonotangle.xsl-illiterate
The first two of these are the TEI source files for the MLP portion itself. The makefile-tangle.tei-entity source file may be used as a starting point for gMLP tangling makefiles elsewhere. The third item is a SYSTEM entity referenced in literate-programming.tei, but less tightly a part of the gMLP source itself. The fourth item is an XSL stylesheet which extracts the code chunks. (At some point in my own development process this was handwritten; as-distributed, it's just a copy of the MLP-generated " graphein-tonotangle.xsl".)
Second, it contains the three shell scripts used to invoke graphein's weaving and tangling processes. These invocations could be done by hand (and thus these scripts extracted from the gMLP source), but they're handy to have from the start.
Third, it contains the gMLP-generated XSLT stylesheet for extracting the code chunks, and makefile for tangling. These could be generated from the items above, but are, again, handy to have from the start.
This makefile may be used, literally, as a template for tangling makefiles in other directories, or its gMLP source (see above) can be used for gMLP variants.
Fourth, it contains a script which runs the Saxon XSLT processor standalone. This "illiterate" version is just a copy of the gMLP version described earlier. This script is useful (but the very useful) only if rebuilding the gMLP system from source.
Finally, it may or may not contain the example shell script " hello.sh", depending on how I copy things.
To regenerate the system from the source, should you wish to do so:
./run-make-tangle.sh clean cp graphein-tonotangle.xsl-illiterate graphein-tonotangle.xsl cp run-saxon.sh-illiterate run-saxon.sh ./run-saxon.sh literate-programming.tei > literate-programming.nw notangle -t8 -Rmakefile-tangle literate-programming.nw > makefile-tangle notangle -t8 -Rrun-make-tangle.sh literate-programming.nw > run-make-tangle.sh notangle -t8 -Rrun-make-weave.sh literate-programming.nw > run-make-weave.sh notangle -t8 -Rrun-make-weave-and-tangle.sh literate-programming.nw > run-make-weave-and-tangle.sh chmod +x run-make-*.sh ./run-make-weave-and-tangle.sh
This requires most of the full complement of graphein tools (described elsewhere), including: an XSLT processor (Saxon, here), the XML Commons Resolver (installed and configured), the TEI P5, xmllint , Noweb ( notangle only), GNU make , bash , and Awk.
To use the system, copy these components (and the components use for weaving) into the " new-static-files " subdirectory of the root directory of the graphein hierarchy.
1.9. Quick Summary of gMLP Coding
A. To declare a code chunk in a graphein TEI source file:
<ab type="code-chunk" xml:id="CodeChunksOwnNameHere"> Code chunk here </ab>
B. (Note) No asterisk for default code chunk name.
C. To declare, in a graphein TEI source file, a link between code chunks:
<seg type="code-chunk-ref">CodeChunkReferredToNameHere</seg>
D. To declare a code chunk which is defined in an XML "SYSTEM" entity (in a separate file):
<!DOCTYPE TEI PUBLIC "-//TEI P5//DTD Main Document Type//EN" "tei.dtd" [ ... regular entity declarations here ... <!ENTITY EntityName SYSTEM "FileName.tei-entity"> ]>
D.1. To show (weave) and use (tangle) it:
&EntityName;
D.2. To show (weave) but not use (tangle) it:
<ab type="do-not-tangle"> &EntityName; <ab>
E. Using less-than and greater-than signs in gMLP source files: